Improving Tezos Storage : update and beta-testing
In a previous post, we presented some work that we did to improve the quantity of storage used by the Tezos node. Our post generated a lot of comments, in which upcoming features such as garbage collection and pruning were introduced. It also motivated us to keep working on this (hot) topic, and we present here our new results, and current state. Irontez3 is a new version of our storage system, that we tested both on real traces and real nodes. We implemented a garbage-collector for it, that is triggered by an RPC on our node (we want the user to be able to choose when it happens, especially for bakers who might risk losing a baking slot), and automatically every 16 cycles in our traces.
In the following graph, we present the size of the context database during a full trace execution (~278 000 blocks):
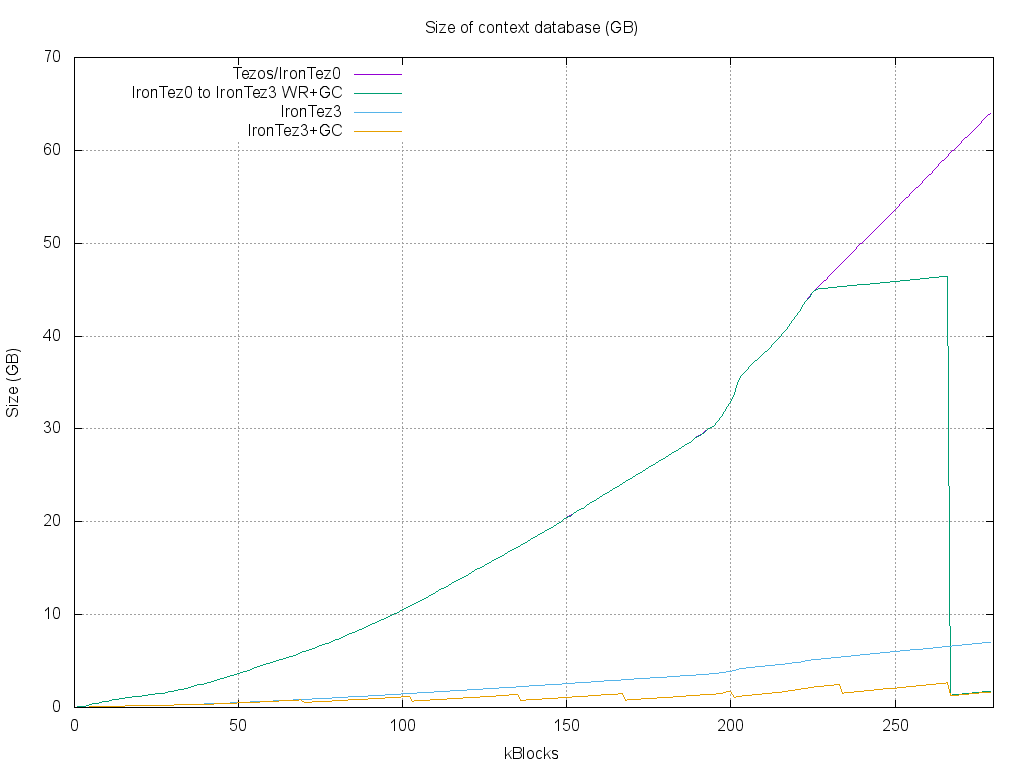
There is definitely quite some improvement brought to the current Tezos implementation based on Irmin+LMDB, that we reimplemented as IronTez0. IronTez0 allows an IronTez node to read a database generated by the current Tezos and switch to the IronTez3 database. At the bottom of the graph, IronTez3 increases very slowly (about 7 GB at the end), and the garbage-collector makes it even less expensive (about 2-3 GB at the end). Finally, we executed a trace where we switched from IronTez0 to IronTez3 at block 225 000. The graph shows that, after the switch, the size immediately grows much more slowly, and finally, after a garbage collection, the storage is reduced to what it would have been with IronTez3.
Now, let’s compare the speed of the different storages:
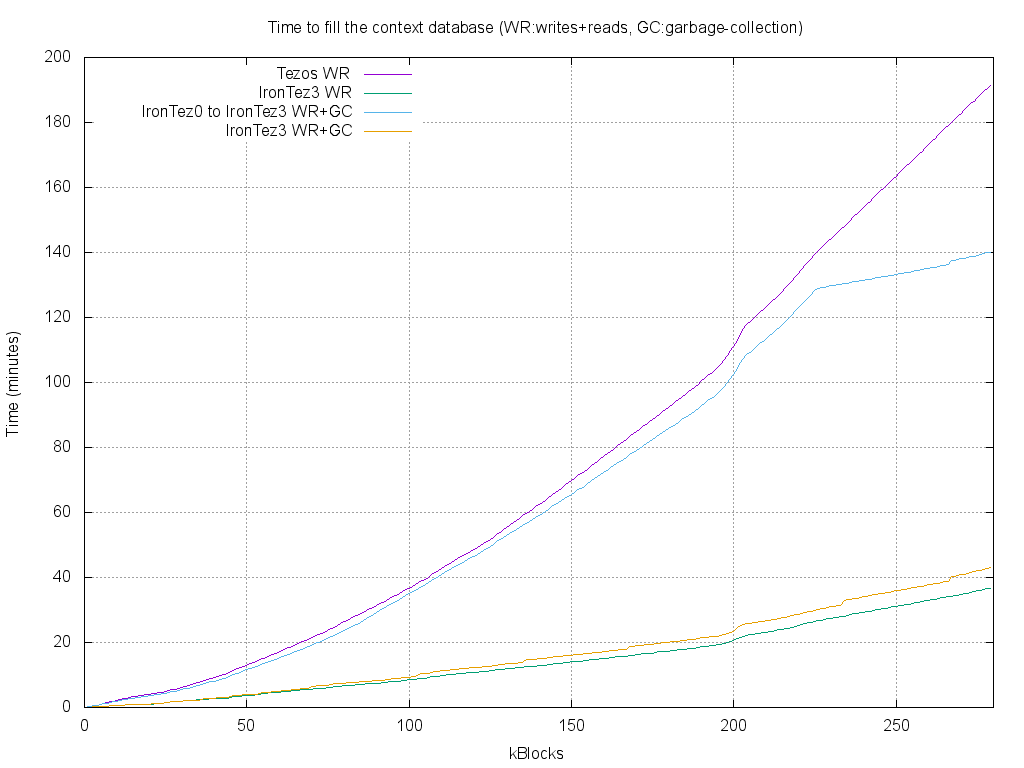
The graph shows that IronTez3 is about 4-5 times faster than Tezos/IronTez0. Garbage-collections have an obvious impact on the speed, but clearly negligible compared to the current performance of Tezos. On our computer used for the traces, a Xeon with an SSD disk, the longest garbage collection takes between 1 and 2 minutes, even when the database was about 40 GB at the beginning.
In the former post, we didn’t check the amount of memory used by our storage system. It might be expected that the performance improvement could be associated with a more costly use of memory… but such is not the case :
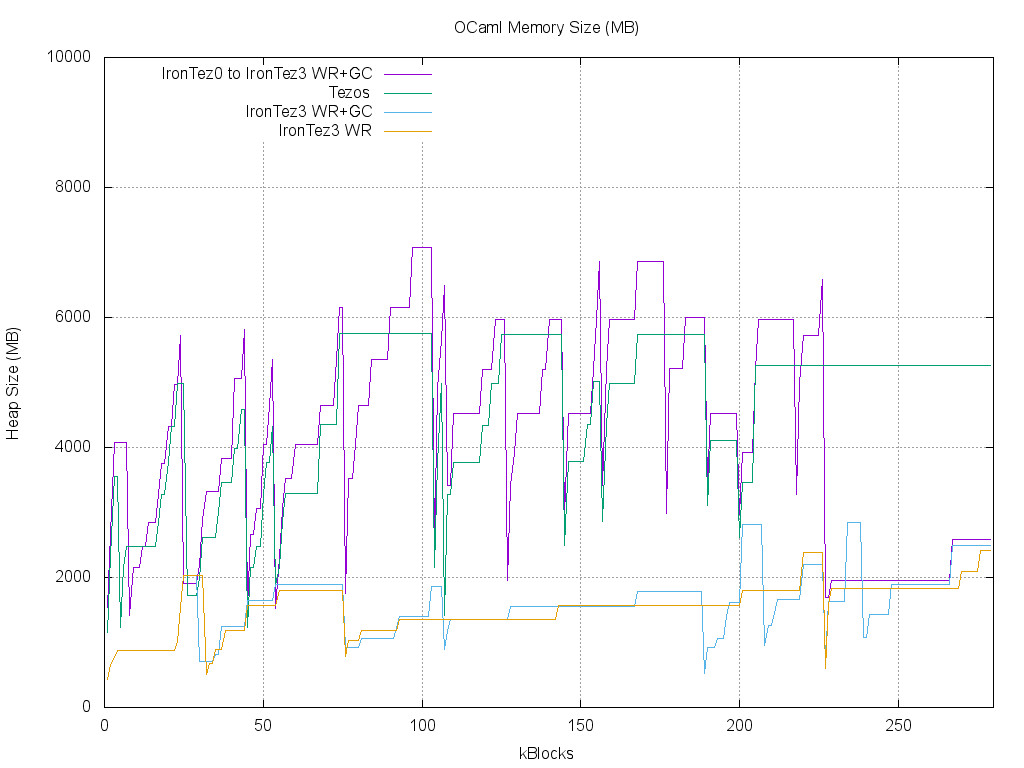
At the top of the graph is our IronTez0 implementation of the current storage: it uses a little more memory than the current Tezos implementation (about 6 GB), maybe because it shares data structures with IronTez3, with fields that are only used by IronTez3 and could be removed in a specialized version. IronTez3 and IronTez3 with garbage collection are at the bottom, using about 2 GB of memory. It is actually surprising that the cost of garbage collections is very limited.
On our current running node, we get the following storage:
$ du
1.4G ./context
4.9G ./store
6.3G .
Now, if we use our new RPC to revert the node to Irmin (taking a little less than 8 minutes on our computer), we get :
$ du
14.3G ./context
4.9G ./store
19.2G .
Beta-Testing with Docker
If you are interested in these results, it is now possible to test our node: we created a docker image, similar to the ones of Tezos. It is available on Docker Hub (one image that works for both Mainnet and Alphanet). Our script mainnet.sh (http://tzscan.io/irontez/mainnet.sh) can be used similarly to the alphanet.sh script of Tezos to manage the container. It can be run on an existing Tezos database, it will switch it to IronTez3. Note that such a change is not irreversible, still it might be a good idea to backup your Tezos node directory before, as (1) migrating back might take some time, (2) this is a beta-testing phase, meaning the code might still hide nasty bugs, and (3) the official node might introduce a new incompatible format.
New RPCS
Both of these RPCs will make the node TERMINATE once they have completed. You should restart the node afterwards.
The RPC /ocp/storage/gc : it triggers a garbage collection using the
RPC /ocp/storage/gc . By default, this RPC will keep only the
contexts from the last 9 cycles. It is possible to change this value
by using the ?keep argument, and specify another number of contexts to
keep (beware that if this value is too low, you might end up with a
non-working Tezos node, so we have set a minimum value of 100). No
garbage-collection will happen if the oldest context to keep was
stored in the Irmin database. The RPC /ocp/storage/revert : it
triggers a migration of the database fron Irontez3 back to Irmin. If
you have been using IronTez for a while, and want to go back to the
official node, this is the way. After calling this RPC, you should not
run IronTez again, otherwise, it will restart using the IronTez3
format, and you will need to revert again. This operation can take a
lot of time, depending on the quantity of data to move between the two
formats.
Following Steps
We are now working with the team at Nomadic Labs to include our work in the public Tezos code base. We will inform you as soon as our Pull Request is ready, for more testing ! If all testing and review goes well, we hope it can be merged in the next release !
Comments
Jack (30 January 2019 at 15 h 30 min):
Please release this as a MR on gitlab so those of us not using docker can start testing the code.
Fabrice Le Fessant (10 February 2019 at 15 h 39 min):
That was done: here
About OCamlPro:
OCamlPro is a R&D lab founded in 2011, with the mission to help industrial users benefit from experts with a state-of-the-art knowledge of programming languages theory and practice.
- We provide audit, support, custom developer tools and training for both the most modern languages, such as Rust, Wasm and OCaml, and for legacy languages, such as COBOL or even home-made domain-specific languages;
- We design, create and implement software with great added-value for our clients. High complexity is not a problem for our PhD-level experts. For example, we helped the French Income Tax Administration re-adapt and improve their internally kept M language, we designed a DSL to model and express revenue streams in the Cinema Industry, codename Niagara, and we also developed the prototype of the Tezos proof-of-stake blockchain from 2014 to 2018.
- We have a long history of creating open-source projects, such as the Opam package manager, the LearnOCaml web platform, and contributing to other ones, such as the Flambda optimizing compiler, or the GnuCOBOL compiler.
- We are also experts of Formal Methods, developing tools such as our SMT Solver Alt-Ergo (check our Alt-Ergo Users' Club) and using them to prove safety or security properties of programs.
Please reach out, we'll be delighted to discuss your challenges: contact@ocamlpro.com or book a quick discussion.
Most Recent Articles
2024
2023
- Maturing Learn-OCaml to version 1.0: Gateway to the OCaml World
- The latest release of Alt-Ergo version 2.5.1 is out, with improved SMT-LIB and bitvector support!
- 2022 at OCamlPro
- Autofonce, GNU Autotests Revisited
- Sub-single-instruction Peano to machine integer conversion
- Statically guaranteeing security properties on Java bytecode: Paper presentation at VMCAI 23
- Release of ocplib-simplex, version 0.5
- The Growth of the OCaml Distribution
2022