Improving Tezos Storage
Running a Tezos node currently costs a lot of disk space, about 59 GB for the context database, the place where the node stores the states corresponding to every block in the blockchain, since the first one. Of course, this is going to decrease once garbage collection is integrated, i.e. removing very old information, that is not used and cannot change anymore (PR720 by Thomas Gazagnaire, Tarides, some early tests show a decrease to 14GB ,but with no performance evaluation). As a side note, this is different from pruning, i.e. transmitting only the last cycles for “light” nodes (PR663 by Thomas Blanc, OCamlPro). Anyway, as Tezos will be used more and more, contexts will keep growing, and we need to keep decreasing the space and performance cost of Tezos storage.
As one part of our activity at OCamlPro is to allow companies to
deploy their own private Tezos networks, we decided to experiment with
new storage layouts. We implemented two branches: our branch
IronTez1 is based on a full LMDB database, as Tezos currently, but
with optimized storage representation ; our branch IronTez2 is based
on a mixed database, with both LMDB and file storage.
To test these branches, we started a node from scratch, and recorded all the accesses to the context database, to be able to replay it with our new experimental nodes. The node took about 12 hours to synchronize with the network, on which about 3 hours were used to write and read in the context database. We then replayed the trace, either only the writes or with both reads and writes.
Here are the results:
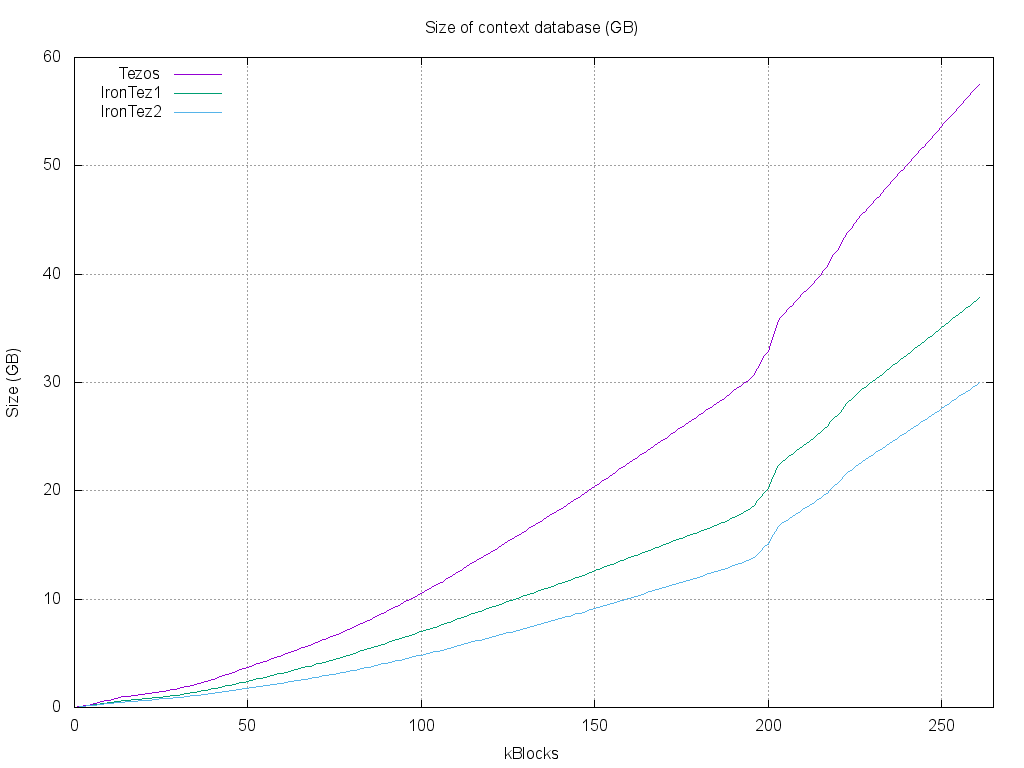
The mixed storage is the most interesting: it uses half the storage of a standard Tezos node !
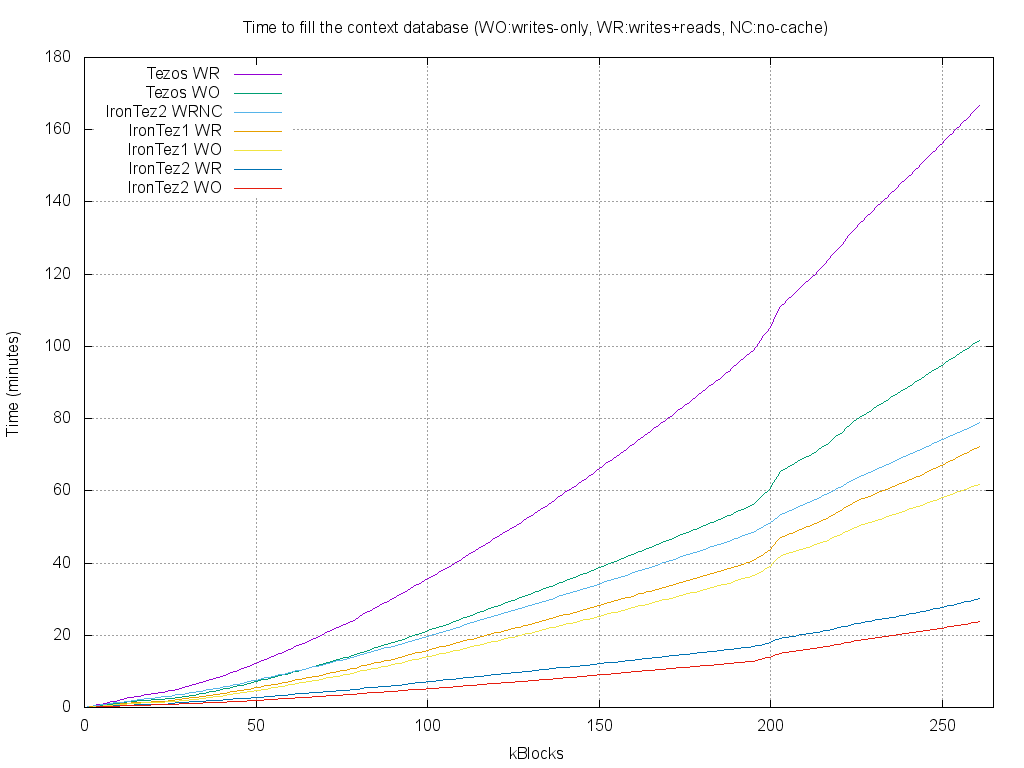
Again, the mixed storage is the most efficient : even with reads and
writes, IronTez2 is five time faster than the current Tezos storage.
Finally, here is a graph that shows the impact of the two attacks that happened in November 2018, and how it can be mitigated by storage improvement:
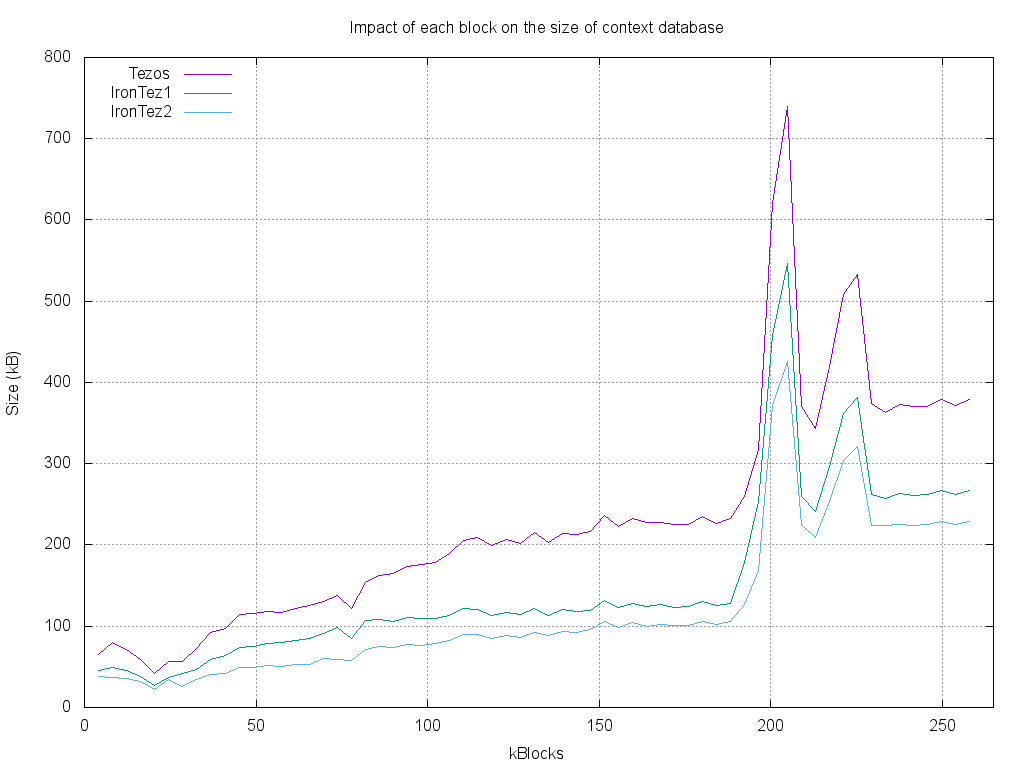
The graph shows that, using mixed storage, it is possible to restore the storage growth of Tezos to what it was before the attack !
Interestingly, although these experiments have been done on full traces, our branches are completely backward-compatible : they could be used on an already existing database, to store the new contexts in our optimized format, while keeping the old data in the ancient format.
Of course, there is still a lot of work to do, before this work is finished. We think that there are still more optimizations that are possible, and we need to test our branches on running nodes for some time to get confidence (TzScan might be the first tester !), but this is a very encouraging work for the future of Tezos !
About OCamlPro:
OCamlPro is a R&D lab founded in 2011, with the mission to help industrial users benefit from experts with a state-of-the-art knowledge of programming languages theory and practice.
- We provide audit, support, custom developer tools and training for both the most modern languages, such as Rust, Wasm and OCaml, and for legacy languages, such as COBOL or even home-made domain-specific languages;
- We design, create and implement software with great added-value for our clients. High complexity is not a problem for our PhD-level experts. For example, we helped the French Income Tax Administration re-adapt and improve their internally kept M language, we designed a DSL to model and express revenue streams in the Cinema Industry, codename Niagara, and we also developed the prototype of the Tezos proof-of-stake blockchain from 2014 to 2018.
- We have a long history of creating open-source projects, such as the Opam package manager, the LearnOCaml web platform, and contributing to other ones, such as the Flambda optimizing compiler, or the GnuCOBOL compiler.
- We are also experts of Formal Methods, developing tools such as our SMT Solver Alt-Ergo (check our Alt-Ergo Users' Club) and using them to prove safety or security properties of programs.
Please reach out, we'll be delighted to discuss your challenges: contact@ocamlpro.com or book a quick discussion.
Most Recent Articles
2025
2024
- opam 2.3.0 release!
- Optimisation de Geneweb, 1er logiciel français de Généalogie depuis près de 30 ans
- Alt-Ergo 2.6 is Out!
- Flambda2 Ep. 3: Speculative Inlining
- opam 2.2.0 release!
- Flambda2 Ep. 2: Loopifying Tail-Recursive Functions
- Fixing and Optimizing the GnuCOBOL Preprocessor
- OCaml Backtraces on Uncaught Exceptions
- Opam 102: Pinning Packages
- Flambda2 Ep. 1: Foundational Design Decisions
- Behind the Scenes of the OCaml Optimising Compiler Flambda2: Introduction and Roadmap
- Lean 4: When Sound Programs become a Choice
- Opam 101: The First Steps
2023