OCamlPro Highlights: Feb 2014
Here is a short report of some of our activities in February 2014 !
Displaying what OPAM is doing
After releasing version 1.1.1, we have been very busy preparing the next big things for OPAM. We have also steadily been improving stability and usability, with a focus on friendly messages: for example, there is a whole new algorithm to give the best explanations on what OPAM is going to do and why:
With OPAM 1.1.1, you currently get this information:
## opam install custom_printf.109.15.00
The following actions will be performed:
– remove pa_bench.109.55.02
– downgrade type_conv.109.60.01 to 109.20.00 [required by comparelib, custom_printf]
– downgrade uri.1.4.0 to 1.3.11
– recompile variantslib.109.15.03 [use type_conv]
– downgrade sexplib.110.01.00 to 109.20.00 [required by custom_printf]
– downgrade pa_ounit.109.53.02 to 109.18.00 [required by custom_printf]
– recompile ocaml-data-notation.0.0.11 [use type_conv]
– recompile fieldslib.109.20.03 [use type_conv]
– recompile dyntype.0.9.0 [use type_conv]
– recompile deriving-ocsigen.0.5 [use type_conv]
– downgrade comparelib.109.60.00 to 109.15.00
– downgrade custom_printf.109.60.00 to 109.15.00
– downgrade cohttp.0.9.16 to 0.9.15
– recompile cow.0.9.1 [use type_conv, uri]
– recompile github.0.7.0 [use type_conv, uri]
0 to install | 7 to reinstall | 0 to upgrade | 7 to downgrade | 1 to remove
With the next trunk version of OPAM, you will get the much more informative output on real dependencies:
## opam install custom_printf.109.15.00
The following actions will be performed:
– remove pa_bench.109.55.02 [conflicts with type_conv, pa_ounit]
– downgrade type_conv from 109.60.01 to 109.20.00 [required by custom_printf]
– downgrade uri from 1.4.0 to 1.3.10 [uses sexplib]
– recompile variantslib.109.15.03 [uses type_conv]
– downgrade sexplib from 110.01.00 to 109.20.00 [required by custom_printf]
– downgrade pa_ounit from 109.53.02 to 109.18.00 [required by custom_printf]
– recompile ocaml-data-notation.0.0.11 [uses type_conv]
– recompile fieldslib.109.20.03 [uses type_conv]
– recompile dyntype.0.9.0 [uses type_conv]
– recompile deriving-ocsigen.0.5 [uses type_conv]
– downgrade comparelib from 109.60.00 to 109.15.00 [uses type_conv]
– downgrade custom_printf from 109.60.00 to 109.15.00
– downgrade cohttp from 0.9.16 to 0.9.14 [uses sexplib]
– recompile cow.0.9.1 [uses type_conv]
– recompile github.0.7.0 [uses uri, cohttp]
0 to install | 7 to reinstall | 0 to upgrade | 7 to downgrade | 1 to remove
Failsafe behaviour is being much improved as well, because things do happen to go wrong when you access the network to download packages and then compile them, and that was the biggest source of problems for our users: errors are now more tightly controlled in each stage of the opam command.
For example, nothing will be changed in case of a failed or interrupted download, and if you press C-c in the middle of an action, you’ll get something like this:
[ERROR] User interruption while waiting for sub-processes
[ERROR] Failure while processing typerex.1.99.6-beta
=-=-= Error report =-=-=
These actions have been completed successfully
install conf-gtksourceview.2
upgrade cmdliner from 0.9.2 to 0.9.4
The following failed
install typerex.1.99.6-beta
Due to the errors, the following have been cancelled
install ocaml-top.1.1.2
install ocp-index.1.0.2
install ocp-build.1.99.6-beta
recompile alcotest.0.2.0
install ocp-indent.1.4.1
install lablgtk.2.16.0
The former state can be restored with opam switch import -f “<xxx>.export”
You also shouldn’t have to dig anymore to find the most meaningful error when something fails.
With the ever-increasing number of packages and versions, resolving requests becomes a real challenge and we’re glad we made the choice to rely on specialized solvers. The built-in heuristics may show its limits when attempting long-delayed upgrades, and everybody is encouraged to install an external solver (aspcud being the one supported at the moment).
Consequently, we have also been working more tightly with the Mancoosi team at IRILL to improve interaction with the solver, and how the user can get the best of it is now well documented, thanks to Roberto Di Cosmo.
Per-projects OPAM Switches with ocp-manager
At OCamlPro, we often use OPAM with multiple switches, to test whether our tools are working with different versions of OCaml, including the new ones that we are developing. Switching between versions is not always as intuitive as we would like, as we sometimes forget to call
$ eval `opam config env`
in the right location or at the good time, and end up compiling a project with a different version of OCaml that we would have liked.
It was quite surprising to discover that a tool that we had developed a long time ago, ocp-manager, would actually become a solution for us to a problem that appeared just now with OPAM: ocp-manager
was a tool we used to switch between different versions of OCaml before
OPAM. It would use a directory of wrappers, one for each OCaml tool,
and by adding this directory once and for all to the PATH, with:
$ eval `ocp-manager -config`
You would be able to switch to OPAM switch 3.12.1 (that needs to have been installed first with OPAM) immediatly by using:
[code language=”bash” gutter=”false”]
$ ocp-manager -set opam:3.12.1
Nothing much different from OPAM ? The nice thing with ocp-manager
is that wrappers also use environment variables and per-directory
information to choose the OCaml version of the tool they are going to
run. For example, if some top-directory of your project contains a file .ocp-switch
with the line “opam:4.01.0”, your project will always be compiled with
this version of OCaml, even if you change the global per-user
configuration. You can also override the global and local configuration
by setting the OCAML_VERSION environment variable.
Maybe ocp-manager can also be useful for you. Just install it with opam install ocp-manager,
change your shell configuration to add its directory to your PATH, and
check if it also works for you (the manpage can be very useful!).
Optimization Patches for ocamlopt under Reviewing Process
This month, we also spent a lot of time improving the optimization patches that we submitted for inclusion into OCaml, and that we have described in our previous blog posts. Mark Shinwell from Jane Street and Gabriel Scherer from INRIA kindly accepted to devote some of their time in a thorough reviewing process, leading to many improvements in the readability and maintenability of our optimization code. As this first patch is a prerequisite for our next patches, we also spent a lot of time propagating these modifications, so that we will be able to submit them faster once this one has been merged!
Displaying the Distribution of Block Sizes with ocp-memprof
In our study to understand the memory behavior of OCaml applications, we have investigated the distribution of block sizes, both in the heap (live blocks) and in the free list (dead blocks). This information should help the programmer to understand which GC parameters might be the best ones for his application, by showing the fragmentation of the heap and the time spent searching in the free list. It is all the more important that improving the format of the free list with bins has been discussed lately in the Core team.
Here, we display the distribution of blocks at a snapshot during the execution of why3replayer, a tool that we are trying to optimize during the Bware Project. The number of free blocks is displayed darker than live blocks, from size 21 to size 0.
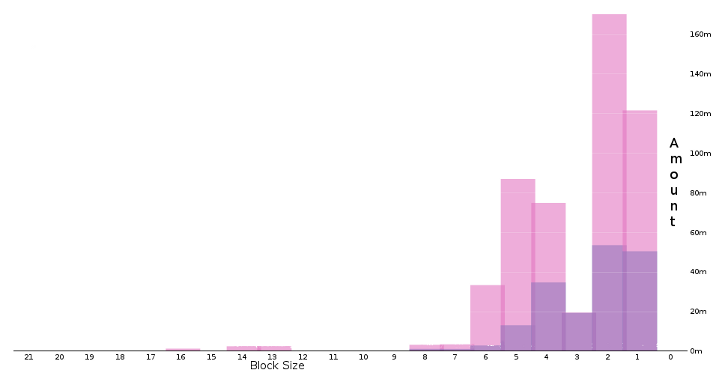
It is interesting to notice that, for this applications, almost all allocations have a size smaller than 6. We are planning to use such information to simulate the cost of allocation for this application, and see which data structure for the free list would benefit the most to the performance of the application.
Whole Program Analysis
The static OCaml analyszer is going quite well. Our set of (working) test samples is growing in size and complexity. Our last improvement was what is called widening. What’s widening ? Well, the main idea is “when I go through a big loop 5000 times, I don’t want the analyzer to do that too”. If we take this sample test:
let () = for i = 0 to 5000 do () done
Without widening, the analysis would loop 5000 times through that
loop. That’s quite useless, not to mention that replacing 5000 by Random.int () would make the analysis loop until max_int (2^62 times on a 64-bits computer) ! Worse, let’s take this code:
let () =
let x = ref 0 in
for i = 1 to 10 do
x := !x + 1
done
Here, the analysis would not see that the increment on !x and i would be linked (that’s one of the aproximations we do to make the computation doable). So, the analyzer does not loop ten times, but again 2^62 times: we do not want that to happen.
The good news now: we can say to the analyzer “every time you go through a loop, check what integers you incremented, and suppose you’ll increment them again and again until you can’t”. This way we only go twice through our for-loop: first to discover it, then to propagate the widening approximation.
Of course this is not that simple, and we’ll often loose information by doing only two iterations. But in most cases, we don’t need it or we can get it in a quicker way than iterating billions of times through a small loop.
Hopefully, we’ll soon be able to analyze any simple program that uses only Pervasives and the basic language features, but for and while loops are already a good starting point !
SPARK 2014: a Use-Case of Alt-Ergo
The SPARK toolset, developped by the AdaCore company, targets the verification of programs written in the SPARK language; a subset of Ada used in the design of critical systems. We published this month a use-case of Alt-Ergo that explains the integration of our solver as a back-end of the next generation of SPARK.
Discussions with SPARK 2014 developpers were very important for us to understand the strengths of Alt-Ergo for them and what would be improved in the solver. We hope this use-case will be helpful for IT solutions providers that would need an automatic solver in their products.
Scilab 5 or Scilab 6 ?
We are still working at improving the Scilab environment with new
tools written in OCaml. We are soon going to release a new version of Scilint,
our style-checking tool for Scilab code, with a new parser compatible
with Scilab 5 syntax. Changing the parser of Scilint was not an easy
job: while our initial parser was partially based on the yacc parser of
the future Scilab 6, we had to write the new parser from scratch to
accept the more tolerant syntax of Scilab 5. It was also a good
opportunity to design a cleaner AST than the one copied from Scilab 6:
written in C++, Scilab 6 AST would for example have all AST nodes
inherit from the Exp class, even instructions or the list of parameters of a function prototype !
We have also started to work on a type-system for Scilab. We want the result to be a type language expressive enough to express, say, the (dependent) sizes of matrices, yet simple enough for clash messages not to be complete black magic for Scilab programmers. This is not simple. In particular, there is the other constraint to build a versatile type system that could serve a JIT or give usable information to the programmer. Which means that the type environment is a mix of static information coming from the inference and of annotations, and dynamic information gotten by introspection of the dynamic interpreter.
In the mean time, we are also planning to write a simpler JIT, to mitigate the impatience of Scilab programmers expecting to feel the underlying power of OCaml!
About OCamlPro:
OCamlPro is a R&D lab founded in 2011, with the mission to help industrial users benefit from experts with a state-of-the-art knowledge of programming languages theory and practice.
- We provide audit, support, custom developer tools and training for both the most modern languages, such as Rust, Wasm and OCaml, and for legacy languages, such as COBOL or even home-made domain-specific languages;
- We design, create and implement software with great added-value for our clients. High complexity is not a problem for our PhD-level experts. For example, we helped the French Income Tax Administration re-adapt and improve their internally kept M language, we designed a DSL to model and express revenue streams in the Cinema Industry, codename Niagara, and we also developed the prototype of the Tezos proof-of-stake blockchain from 2014 to 2018.
- We have a long history of creating open-source projects, such as the Opam package manager, the LearnOCaml web platform, and contributing to other ones, such as the Flambda optimizing compiler, or the GnuCOBOL compiler.
- We are also experts of Formal Methods, developing tools such as our SMT Solver Alt-Ergo (check our Alt-Ergo Users' Club) and using them to prove safety or security properties of programs.
Please reach out, we'll be delighted to discuss your challenges: contact@ocamlpro.com or book a quick discussion.
Most Recent Articles
2024
2023
- Maturing Learn-OCaml to version 1.0: Gateway to the OCaml World
- The latest release of Alt-Ergo version 2.5.1 is out, with improved SMT-LIB and bitvector support!
- 2022 at OCamlPro
- Autofonce, GNU Autotests Revisited
- Sub-single-instruction Peano to machine integer conversion
- Statically guaranteeing security properties on Java bytecode: Paper presentation at VMCAI 23
- Release of ocplib-simplex, version 0.5
- The Growth of the OCaml Distribution
2022